
Da die biopharmazeutische Industrie in den nächsten 5 Jahren voraussichtlich um 47 % wachsen wird, sind Daten wichtiger denn je. Daten an sich sind zwar entscheidend für verbesserte Prozesse und Effizienz, müssen aber auf die richtige Weise analysiert und genutzt werden, um ihr Potenzial zu maximieren.
In diesem Artikel befassen wir uns mit den Auswirkungen von Big Data und maschinellem Lernen auf die biopharmazeutische Industrie und damit, wie diese Technologien die Zukunft der pharmazeutischen Produktion verändern und gestalten können.
Was ist Big Data und warum ist es wichtig?
Während Daten an sich schon einen eigenen Wert haben, sind Big Data die Grundlage für gute Analysen, die letztlich hilfreiche und aussagekräftige Erkenntnisse zur Verbesserung von Prozessen, Effizienz und Produktivität liefern. Bei Big Data handelt es sich um eine Kombination strukturierter und unstrukturierter Daten, die in der Regel in großen Mengen gesammelt werden und dann für maschinelle Lernprojekte, Vorhersagemodelle und andere fortschrittliche Analyseanwendungen genutzt werden können.
Was Big Data von anderen Daten unterscheidet, ist in der Regel seine;
- Umfang
- Geschwindigkeit (bezieht sich darauf, wie schnell Daten erzeugt, gesammelt und analysiert werden können)
- Komplexität
Die Menge der erfassten Daten kann in Terabytes an Informationen und Speicherplatz berechnet werden. Die Analyse solch großer Datenmengen kann Muster und Trends in der Vergangenheit aufdecken, Veränderungen in Echtzeit erkennen und sogar aussagekräftige Prognosen für die Zukunft erstellen.
Big Data kann unterteilt werden in:
Strukturierte Daten: Bestehen aus Daten, die durchsuchbar sind und ein vorher festgelegtes und definiertes Format haben. Sie sind in der Regel organisiert und können direkt verwendet werden, ohne dass sie für die Interpretation „bereinigt“ werden müssen.
Unstrukturierte Daten: Umfasst Daten aus verstreuten Quellen, z. B. allgemeine Wirtschafts- und Geschäftsprognosen, Beiträge in sozialen Medien oder Verkehrsdaten. Diese Daten müssen in der Regel bereinigt und für die Interpretation optimiert werden.
Die Bedeutung und Auswirkung von Big Data zeigt sich am besten in der Analytik, bei der durch Data Mining Muster und Beziehungen herausgearbeitet werden, indem eine Veränderung im Status quo der Daten identifiziert wird, und in der prädiktiven Analytik, die historische Daten nutzt, um Vorhersagen über die Zukunft zu treffen – so können wir Risiken und Chancen erkennen. Die Datenquellen in der biopharmazeutischen Industrie sind in der Regel vielfältiger und komplexer und können von allen Beteiligten entlang der Lieferkette stammen, von den Herstellern bis zu den Händlern und sogar den Patienten.
Was ist maschinelles Lernen und warum ist es wichtig?
Maschinelles Lernen ist ein Teilbereich der künstlichen Intelligenz und umfasst den Einsatz von Computersystemen, die sich selbst anpassen und mit Hilfe von Algorithmen und statistischen Modellen lernen können und in der Lage sind, aus Mustern in Datensätzen Rückschlüsse zu ziehen. Mit anderen Worten, es ist definiert als die Fähigkeit, die Art und Weise zu imitieren, wie das menschliche Gehirn lernt.
Ein grundlegender Aspekt des maschinellen Lernens ist die Gewinnung ausreichender Daten, die fast jede Form annehmen können, wie z. B. Telefonnummern, Verkaufsberichte, Sensordaten, Banktransaktionen oder – im Falle der biopharmazeutischen Industrie – Daten wie Patientenakten oder Informationen über Teilnehmer an klinischen Studien.
Maschinelles Lernen kann in drei verschiedene Funktionen unterteilt werden:
- Beschreibend: erklärt, was passiert
- Prädiktiv: nutzt Daten, um zukünftige Ergebnisse vorherzusagen
- präskriptiv: nutzt Daten, um Vorschläge für die nächsten Schritte zu machen
Die Bedeutung des maschinellen Lernens für den biopharmazeutischen Bereich liegt in seiner Fähigkeit, Prozesse zu beschleunigen, sowohl in der Phase der Arzneimittelentdeckung als auch in der Herstellungsphase.
Wie werden Big Data und maschinelles Lernen der Biopharma-Industrie helfen?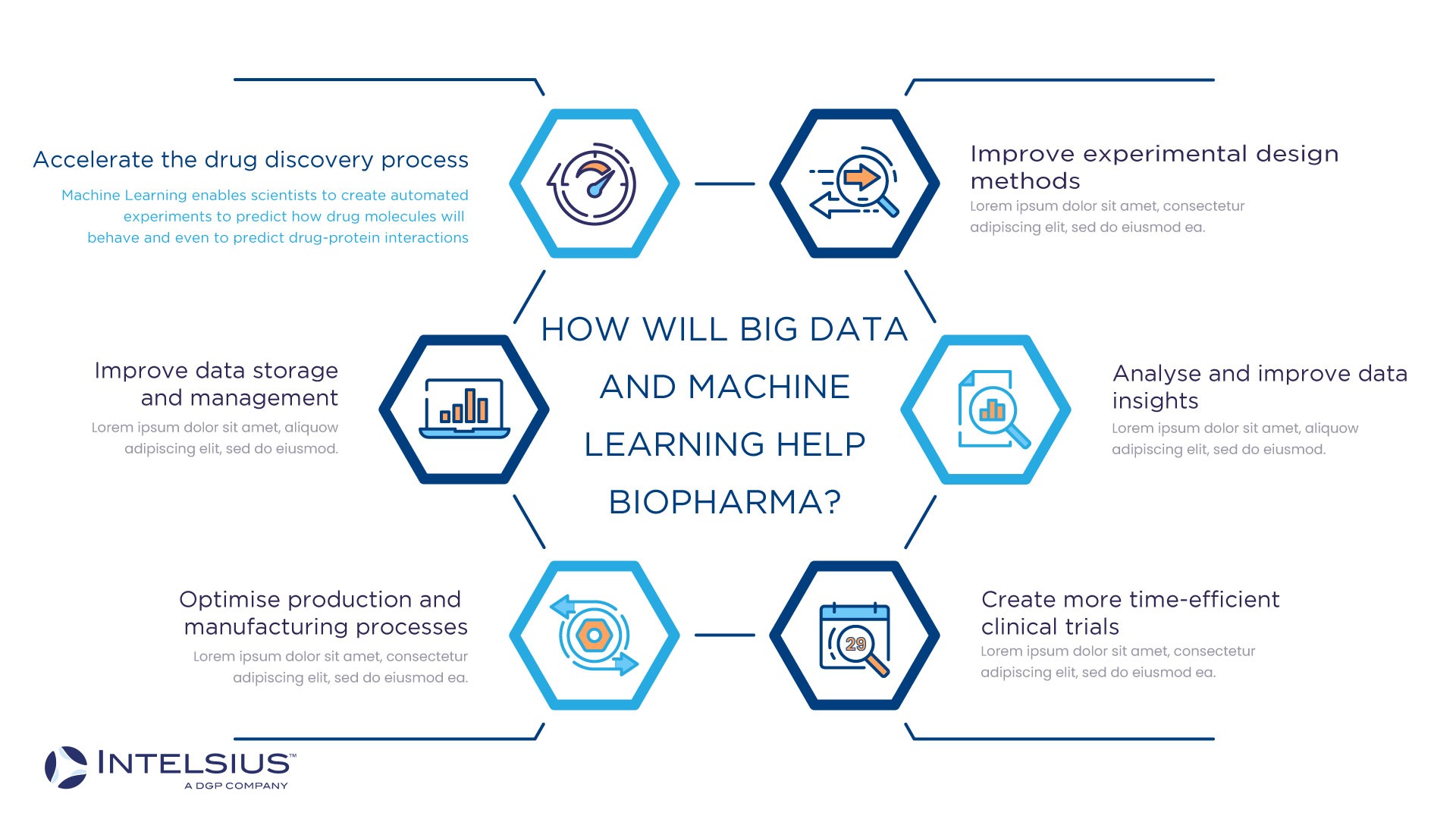
Die biopharmazeutische Industrie ist komplex und verfügt über viele Datenquellen, von den Arzneimittelentwicklern bis hin zu den Herstellern und Vertreibern. Diese Komplexität macht den Bedarf an kohärenten Daten noch wichtiger. Big-Data-Analytik hilft bei der Verwaltung von Daten, der Optimierung von Bestandsprozessen, der Verfolgung von Trends und Abweichungen und der Bereitstellung hilfreicher Markteinblicke.
Die Verwaltung von Daten ist ein wesentlicher Bestandteil der Verbesserung der Effizienz des Biopharmamarktes, da Daten aus allen Teilen der pharmazeutischen Lieferkette stammen, vom Hersteller über die Apotheke bis hin zum Patienten. Dieses komplexe Geschäftsumfeld eignet sich besonders gut für die Nutzung von Big Data, um Prozesse zu beschleunigen und die Effizienz und Genauigkeit der Abläufe in der Branche zu erhöhen.
Big Data und maschinelles Lernen schließen sich nicht gegenseitig aus, sondern können sich sogar ergänzen. Wenn Big Data richtig verwaltet wird, kann es das maschinelle Lernen verbessern, indem es qualitativ hochwertigere relevante Daten für Analysen liefert. Maschinelles Lernen und Big Data haben, wenn sie gemeinsam eingesetzt werden, das Potenzial,:
- Beschleunigung des Prozesses der Arzneimittelentdeckung
- Verbesserung der Methoden zur Versuchsplanung
- Analyse und Verbesserung von Dateneinblicken
- Optimierung von Produktions- und Herstellungsprozessen
- Verbesserung der Datenspeicherung und -verwaltung
Entdeckung von Medikamenten
Wie bereits erwähnt, bedeutet die Technologie des maschinellen Lernens im Wesentlichen, dass Computer in der Lage sind, so zu lernen, wie es Menschen tun. Mit Hilfe des maschinellen Lernens können Wissenschaftler automatisierte Experimente durchführen, um das Verhalten von Arzneimittelmolekülen und sogar die Wechselwirkungen zwischen Arzneimitteln und Proteinen vorherzusagen. Vorhersagen zu können, wie Moleküle reagieren werden, ist entscheidend für die Herstellung eines neuen Medikaments oder einer neuen Behandlung. In der Vergangenheit war dies ein Versuch-und-Irrtum-Prozess, der teuer und zeitaufwändig sein kann. Hier sind Modelle des maschinellen Lernens hilfreich. In einer kürzlich durchgeführten Studie wurde ein datengesteuerter Ansatz entwickelt, bei dem Experimente mit Modellen des maschinellen Lernens kombiniert werden, um die chemische Reaktivität zu verstehen, wodurch die Herstellung von Arzneimitteln wesentlich schneller erfolgen kann.
Klinische Prüfungen
In der Biopharmazie werden während des gesamten Prozesses klinischer Studien Daten wie Protokolle, Patienteninformationen, Labortestergebnisse und mehr gesammelt. Der weltweite Markt für das Outsourcing klinischer Studien wurde im Jahr 2022 auf 40,77 Mrd. USD geschätzt und wird bis 2031 voraussichtlich 74,38 Mrd. USD erreichen. Ziel einer klinischen Prüfung ist es, festzustellen, ob ein Medikament für den Menschen sicher und wirksam ist, ein Prozess, der mühsam und langwierig sein kann.
Eine der Herausforderungen besteht in der Rekrutierungsphase, insbesondere darin, genügend Probanden für die Kontrollgruppe zu rekrutieren. In der Regel bestehen die Kontrollgruppen aus Patienten, die manchmal seltene Krankheiten haben, so dass die Suche nach einwilligungsfähigen Patienten langwierig und nicht immer erfolgreich ist. Durch die Nutzung von Big Data können wir die Notwendigkeit einer anfänglichen Kontrollgruppe ganz abschaffen, indem wir uns Big Data zunutze machen. Dabei handelt es sich um eine Gruppe, die dieselbe Funktion wie eine herkömmliche klinische Studie hat, aber dann eingesetzt werden kann, wenn es besonders schwierig ist, Teilnehmer für eine Kontrollgruppe zu rekrutieren, oder wenn die Krankheit eine sofortige Behandlung erfordert, wie bei Krebs.
Die wahrscheinlich wichtigste unmittelbare Anwendung externer Kontrollgruppen ist die Durchführung von Vorversuchen, die als Grundlage für die Bewertung dienen können, ob sich eine Behandlung für die Durchführung einer vollständigen klinischen Studie lohnt oder nicht.
Herausforderungen bei der Implementierung von Big Data und maschinellem Lernen im biopharmazeutischen Betrieb
Kosten
Die Implementierung von Big Data in den pharmazeutischen Betrieb ist keine leichte Aufgabe. Eine unternehmensweite Implementierung würde ein Budget für die Speicherung der Daten, Analysetools, Cybersicherheit und solide Data-Governance-Programme erfordern. Vor allem in der biopharmazeutischen Industrie müssen Unmengen von Daten nachverfolgt und aufgezeichnet werden, was die Kosten noch weiter in die Höhe treiben könnte.
Schwierigkeiten bei der Beschaffung nützlicher Daten
Nicht alle Daten sind gleich. Die Sicherung der richtigen Art von Daten hat einen großen Einfluss auf die Qualität der Erkenntnisse, die durch Big-Data-Analysen gewonnen werden können. Es ist verständlich, dass nicht alle Daten nützlich oder hilfreich sind, aber die Kosten für die Speicherung, Integration und Analyse dieser minderwertigen Daten werden wahrscheinlich weitere Kosten verursachen als die Verwendung fehlerfreier Daten. Die Komplexität und das Volumen der Daten entlang der biopharmazeutischen Lieferkette können die Sicherung von Qualitätsdaten zu einer größeren Herausforderung machen, ein Faktor, der bei der Implementierung berücksichtigt werden muss. Doppelte Datensätze, ungenaue Informationen und Formatierungsfehler sind einige der häufigsten Probleme mit der Datenqualität, die von den Unternehmen behoben werden müssen. Auch wenn nicht alle Daten fehlerfrei sind, müssen die Unternehmen proaktiv dafür sorgen, dass die Daten regelmäßig geprüft und validiert werden, um ein möglichst aussagekräftiges Analyseergebnis zu erhalten.
Höhere Qualifikation der Mitarbeiter
Die Implementierung von Big Data in allen Bereichen des Unternehmens erfordert auch spezielle Fähigkeiten, was bedeutet, dass neue Mitarbeiter eingestellt oder weitergebildet werden müssen, um die Lücke zu schließen. Da der Markt für qualifizierte Fachkräfte immer härter umkämpft ist, kann es schwierig sein, die richtigen Talente zu finden, und die Kosten dafür können für das Unternehmen erheblich sein. Die Arbeit mit Big Data wird eine Veränderung der Prozesse erfordern, vielleicht von mehr manuellen Aufgaben hin zu einer mehr virtuellen und digitalen Verarbeitung von Informationen und Prozessen. Dies würde weitere Qualifizierungsmaßnahmen im gesamten Unternehmen erfordern, da die Mitarbeiter im Umgang mit den neuen Prozessen geschult und mit dem richtigen Wissen ausgestattet werden müssten, um einen reibungslosen und effizienten Betrieb zu gewährleisten.
Schlussfolgerung
Big Data und maschinelles Lernen werden die biopharmazeutische Industrie durch die Verbesserung von Prozessen, die Verkürzung von Vorlaufzeiten, die Verbesserung der Versuchsplanung und die Verbesserung des Datenmanagements revolutionieren. Die Implementierung dieser neuen Technologien in den täglichen Betrieb ist mit Herausforderungen verbunden, darunter hohe Kosten, die Beschaffung von Talenten und die Schwierigkeit, qualitativ hochwertige Daten zu sichern. Langfristig werden die Vorteile jedoch die Herausforderungen überwiegen, und zwar in Form von verbesserter Effizienz für die Branche und genaueren und wirksameren pharmazeutischen Behandlungen.
Externe Quellen
- Mordor Intelligence
- National Library of Medicine – Machine Learning in Drug Discovery: A Review
- Straits Research
- MIT Technology Review: Clinical trials are better, faster, cheaper with big data
- McKinsey & Company: How big data can revolutionize pharmaceutical R&D
- AJMC: How AI and Machine Learning Can Bring Quality Improvements in Biopharma
- Nature Chemistry: Probing the chemical ‘reactome’ with high-throughput experimentation data